This post is part of a What Is… series that explains spatial audio techniques and terminology.
Ambisonics is a spatial audio system that has been around since the 1970s, with lots of the pioneering work done by Michael Gerzon. Interest in Ambisonics has waxed and waned over the decades but it is finding use in virtual, mixed and augmented reality because it has a number of useful mathematical properties. In this post you’ll find a brief summary of first-order Ambisonics, without going too deeply into the maths that underpins it.
Unlike channel-based systems (stereo, VBAP, etc.) Ambisonics works in two stages: encoding and decoding. The encoding stage converts the signals into B-format (spherical harmonics), which are agnostic of the loudspeaker arrangement. The decoding stage takes these signals and converts them to the loudspeaker signals needed to recreate the scene for the listeners.
Ambisonic Encoding
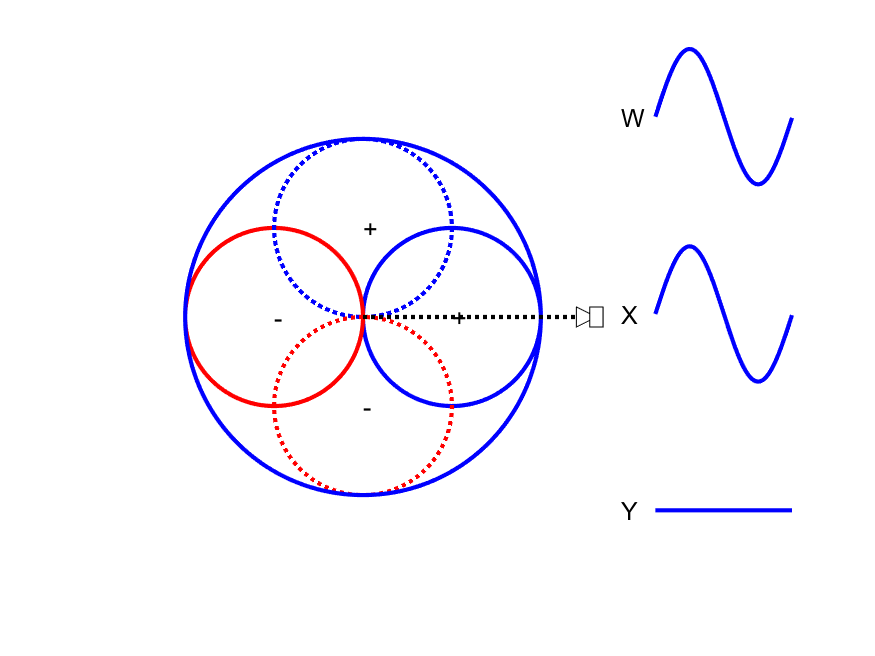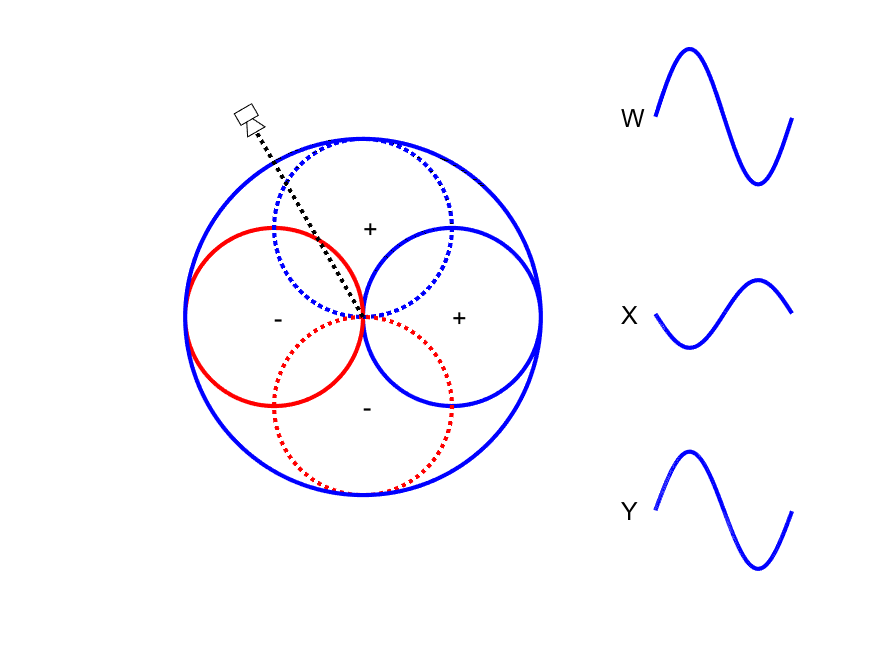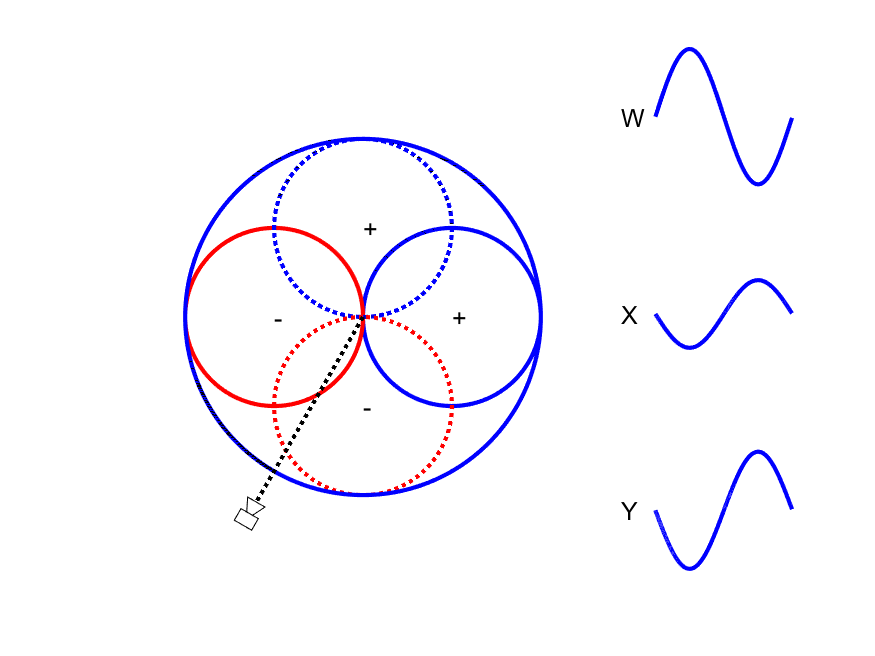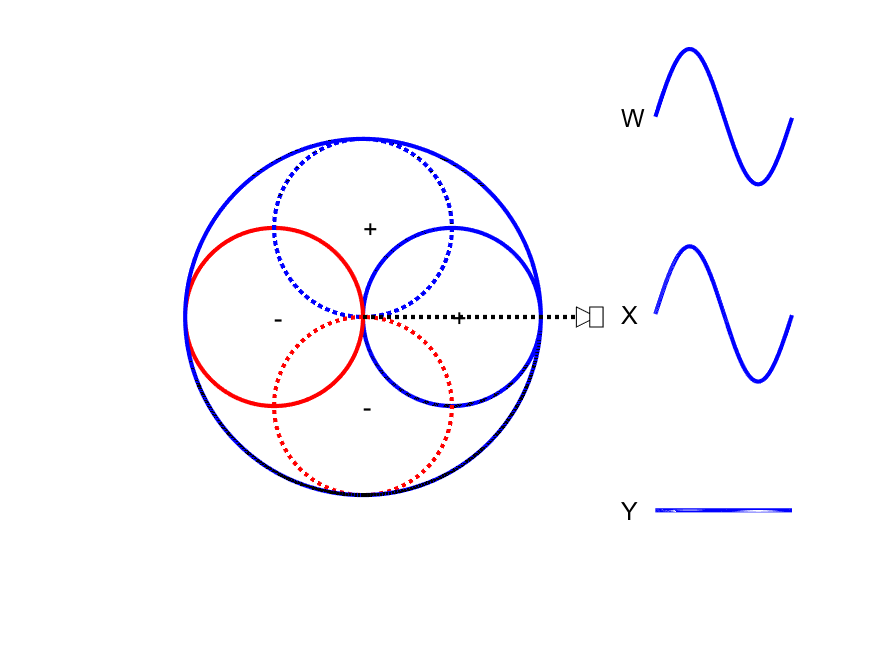 First-order Ambisonic encoding to SN3D for a sound source rotating in the horizontal plane. The Z channel is always zero for these source directions.
First-order Ambisonic encoding to SN3D for a sound source rotating in the horizontal plane. The Z channel is always zero for these source directions.
A mono signal can be encoded to Ambisonics B-format using the following equations:
\(begin{eqnarray}
W &=& S \
Y &=& Ssinthetacosphi \
Z &=& Ssinphi\
X &=& Scosthetacosphi
end{eqnarray}
\)
where (S) is the signal being encoded, (theta) is the azimuthal direction of the source and (phi) is the elevation angle. (These equations use the semi-normalised 3D (SN3D) scheme, as in the AmbiX format used by Google for YouTube. The channel ordering also follows the AmbiX standard.) First-order Ambisonics can also be captured using a tetrahedral microphone array.
B-format is a representation of the sound field at a particular point. Each sound source is encoded and the W, X, Y and Z channels for each source are summed to give the complete sound field. Therefore, no matter how many sound sources are in the scene, only 4 channels are required for transmission.
This encoding can be thought of as capturing a sound source using one omnidirectional microphone (W) and 3 figure-of-eight microphones pointing along the Cartesian x-, y- and z-axes. As shown in the animation to the side, the amplitude of the W channel stays constant for all source positions while the X and Y channels change relatives gains and sign (positive/negative) with source position. Comparison of the polarity of X and Y with W allows the direction of the sound source to be derived.
Ambisonic Decoding
Decoding is the process of taking the B-format signals and converting them to loudspeaker signals. Depending on the loudspeaker layout this can be relatively straightforward or really quite complex. In the most simple cases, with a perfectly regular layout, the B-format signals are sampled at the loudspeaker positions. Other methods, (for example, mode-matching or energy preserving) can be used but tend to give the same results for a regular array.
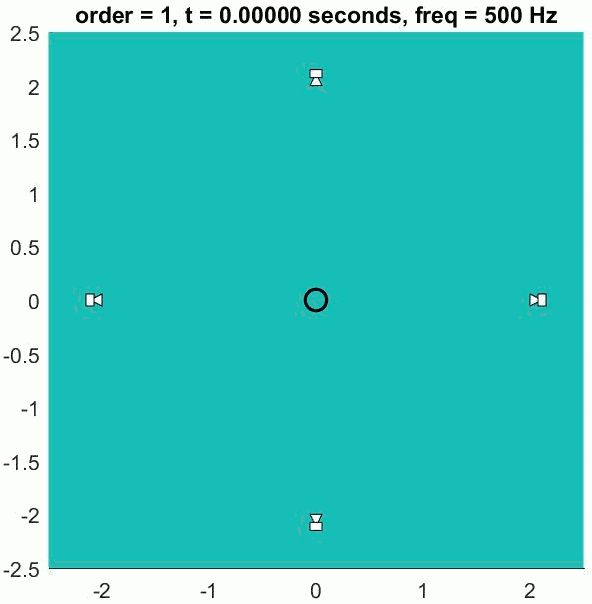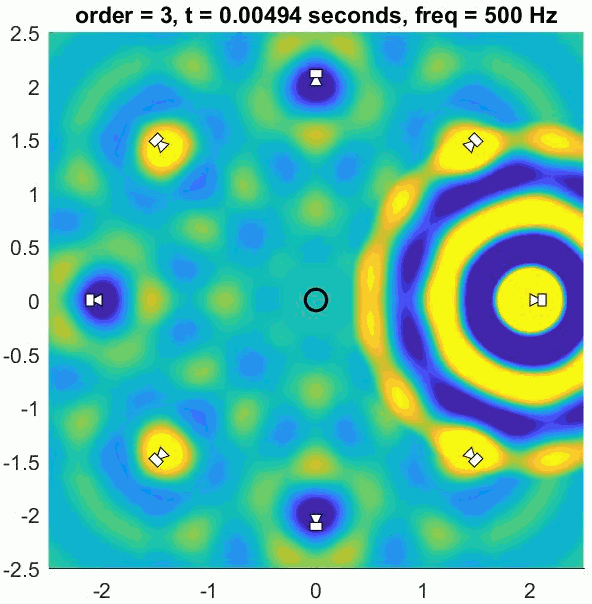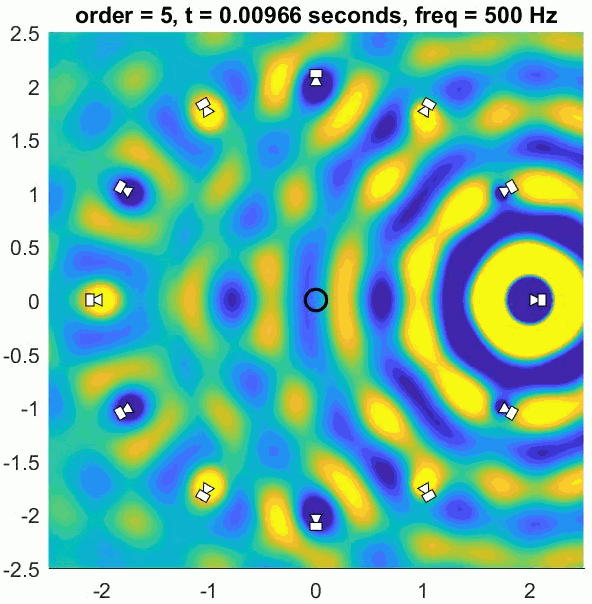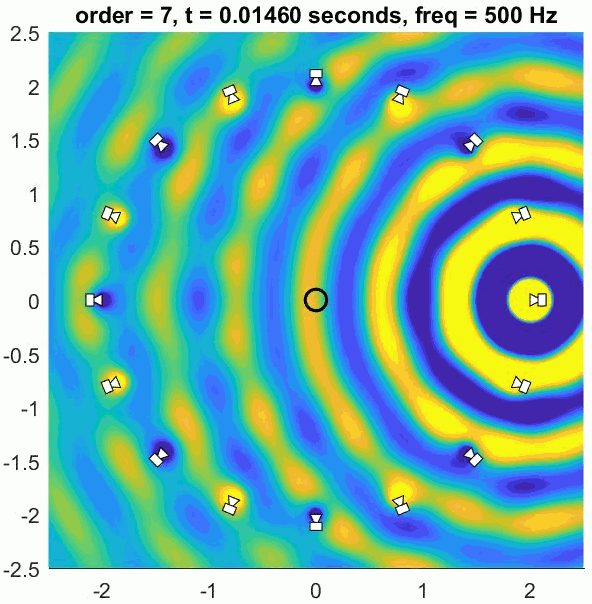
Assuming a regular array and good decoder, an Ambisonic decoder will recreate the exact sound field up to approximately 400 to 700 Hz. Below this limit frequency the reproduction error is low and the ITD cues are well recreated, meaning the system can provide good localisation. Above this frequency the recreated sound field deviates from the intended physical sound field so some psychoacoustic optimisation is applied. This is realised by using a different decoder in higher frequency ranges that focusses the energy in as small a region as possible in the loudspeaker array. This helps produce better ILD cues and a more precise image.
Ambisonics differs from VBAP because, in most cases, all loudspeakers will be active for any particular source direction. Not only will the amplitude vary, the polarity of the loudspeaker signals will also matter. Ambisonics uses all of the loudspeakers to “push” and “pull” so that the correct sound field is recreated at the centre of the loudspeaker array.
What is a Good Decoder?
A “good” Ambisonic decoder requires an appropriate loudspeaker arrangement. Ambisonics ideally uses a regularly positioned loudspeaker arrangement. For example, a horizontal-only system will place the loudspeakers at regular intervals around the centre of an array.
Any number of loudspeakers can be used to decode the sound scene but using more than required can lead to colouration problems. The more loudspeakers are added the more of a low-pass filtering effect there is for listeners in the centre of the array. So what is the best number of loudspeakers to use for first-order Ambisonics? It is generally agreed that 4 loudspeakers placed in a square be used for a horizontal system and 8 in a cuboid be used for 3D playback. This avoids too much colouration and satisfies several conditions for good (well… consistent) localisation.
There are metrics defined in the Ambisonics literature that predict the quality of the system in terms of localisation. These are the velocity and energy vectors and they are deserving of their own article. For now, it’s worth noting that the velocity vector links to low-frequency ITD localisation cues. Decoders are designed to optimise it at low-frequencies while they are optimised using the energy vector at higher frequencies. The high frequency decoder is known as a ‘max rE’ decoder, so-called because it aims to maximise the magnitude of the energy vector metric. This is just another way of saying that the energy is focussed in as small an area as possible.
Ambisonic Rotations
When it comes to virtual and augmented reality, efficient rotation of the full sound field is to follow head movements is a big plus. Thankfully, Ambisonics has got us covered here. The full sound field can be rotated before decoding by blending the X, Y and Z channels correctly.
The advantage of rotating the Ambisonic sound field is that any number of sound sources can be encoded in just 4 channels, meaning rotating a sound field with one sound source takes as much effort as rotating one with 100 sound sources.
That’s the basics of Ambisonics covered. At some point we’ll look more at measures of quality of Ambisonics decoders and how well ITD and ILD are recreated. This blog has also only covered first-order Ambisonics, but Higher Order Ambisonics (HOA) is likely make its way to VR platforms in a significant way in the near future so I’ll cover that soon.
Do you have any spatial audio questions you’d like to have answered? Just leave a comment and let me know!